


1. Introduction
In 2024, 78% of organizations reported using AI in at least one business function, marking a dramatic acceleration from 55% just one year prior. Yet beneath this surge in adoption lies a critical challenge: while building AI models has become increasingly accessible, operationalizing them at enterprise scale remains a formidable barrier. Studies indicate that up to 90% of AI models never make it past the pilot phase, leaving massive value unrealized and creating friction between data science teams and business stakeholders.
The gap between experimentation and production deployment represents one of the most significant obstacles in modern AI implementation. As McKinsey research reveals, only 1% of business leaders consider their AI initiatives to be truly mature, despite widespread investment and enthusiasm. This maturity gap isn't merely technical—it reflects fundamental challenges in managing the complete AI lifecycle, from initial model development through continuous monitoring and improvement in production environments.
Enter AI Lifecycle Management and Machine Learning Operations (MLOps): structured approaches that bridge the divide between data science innovation and operational reliability. This comprehensive guide explores how enterprises can navigate the full AI lifecycle—establishing robust frameworks for model development, deployment, governance, and continuous monitoring that transform experimental models into sustainable, production-grade systems delivering measurable business value.
2. The Importance of AI Lifecycle Management in Modern Enterprises
The escalating strategic importance of AI within organizations demands systematic lifecycle management approaches that extend far beyond initial model creation. With global AI spending projected to reach $644 billion in 2025—representing a 76.4% increase from 2024—enterprises are making substantial commitments that require demonstrable returns on investment.
The Business Case for Structured AI Lifecycle Management
Organizations that successfully operationalize AI at scale report significant competitive advantages:
- Financial Returns: Companies investing strategically in AI deployment see an average ROI of 3.7x on their initial investments, with top performers achieving returns of 10.3 times their investment.
- Productivity Gains: Enterprises with mature AI practices report 15-30% improvements in productivity, customer satisfaction, and retention across AI-enabled workflows.
- Operational Efficiency: Generative AI has helped companies achieve productivity improvements of between 15% and 30%, with early adopters seeing 15.2% cost savings on average.
However, capturing this value requires more than deploying individual models. It demands comprehensive lifecycle management that ensures models remain accurate, compliant, and aligned with evolving business objectives throughout their operational lifespan.
The Maturity Challenge
Despite widespread AI adoption, fewer than 30% of AI investments are tied to explicit performance metrics, and many organizations struggle to demonstrate clear business value from their AI initiatives. This disconnect stems from inadequate lifecycle management practices:
- Pilot Purgatory: Organizations excel at proof-of-concept development but struggle with production scaling, resulting in numerous pilot projects that never deliver enterprise-wide impact.
- Model Degradation: Without continuous monitoring, models left unchanged for 6+ months experience error rate increases of up to 35% due to data drift and environmental changes.
- Governance Gaps: Only 28% of organizations have CEO-level oversight of AI governance, creating accountability voids that hinder strategic alignment and risk management.
Effective AI lifecycle management addresses these challenges by establishing standardized processes, clear ownership structures, and automated workflows that support sustainable AI operations at enterprise scale.
3. Core Stages of the AI Lifecycle
Understanding the complete AI lifecycle is foundational to implementing effective management practices. While specific organizational implementations vary, the lifecycle typically encompasses six interconnected stages that transform business problems into operational AI solutions.
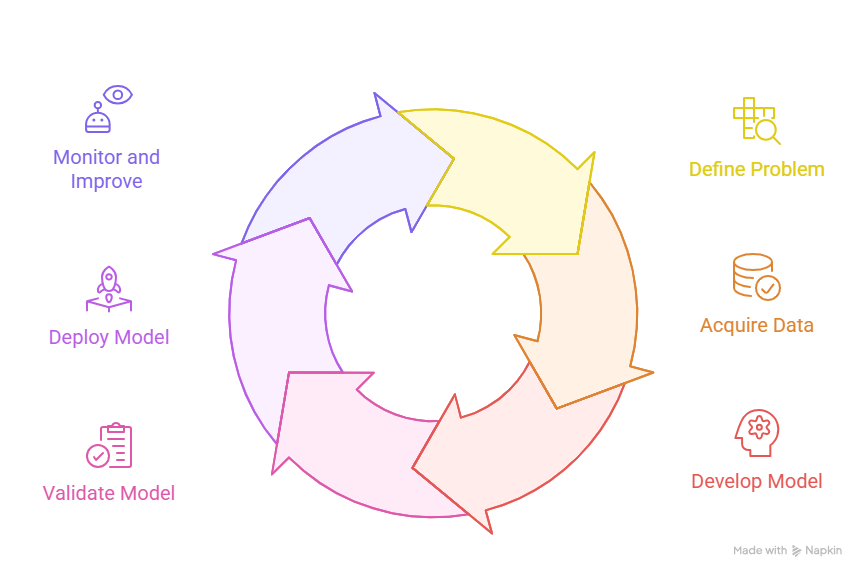
1. Problem Definition and Use Case Identification
The lifecycle begins with clearly articulated business problems and realistic assessments of AI's potential contribution. This stage involves:
- Business Case Development: Quantifying expected value, defining success metrics, and establishing ROI thresholds that justify investment.
- Feasibility Assessment: Evaluating data availability, technical requirements, and organizational readiness before committing resources.
- Stakeholder Alignment: Ensuring executive sponsorship and cross-functional buy-in that supports implementation and adoption.
Organizations with clear AI strategies are five times more likely to realize significant financial benefits, underscoring the importance of thorough upfront planning.
2. Data Acquisition and Preparation
Quality data forms the foundation of effective AI systems. This stage encompasses:
- Data Collection: Aggregating relevant data from internal systems, external sources, and real-time streams.
- Data Cleaning and Validation: Addressing missing values, outliers, and inconsistencies that compromise model accuracy.
- Feature Engineering: Transforming raw data into meaningful features that enhance model performance.
- Data Governance: Implementing controls that ensure data quality, security, and compliance throughout the lifecycle.
Organizations investing in robust data quality and governance are 2.5 times more likely to successfully scale AI initiatives, highlighting the critical nature of this foundational work.
3. Model Development and Training
This stage involves iterative experimentation to develop models that meet performance requirements:
- Algorithm Selection: Choosing appropriate modeling approaches based on problem characteristics and data availability.
- Model Training: Optimizing model parameters through systematic experimentation and hyperparameter tuning.
- Performance Evaluation: Assessing models against validation datasets using relevant metrics (accuracy, precision, recall, F1 score, etc.).
- Model Versioning: Maintaining comprehensive records of model iterations, training data, and performance metrics for reproducibility and governance.
Modern development practices emphasize collaboration between data scientists, domain experts, and engineers to ensure models address actual business requirements while maintaining technical rigor.
4. Model Validation and Testing
Before production deployment, models undergo rigorous validation:
- Statistical Validation: Confirming models generalize effectively to unseen data and avoid overfitting.
- Bias Detection: Identifying and mitigating potential discrimination across demographic segments or operational scenarios.
- Adversarial Testing: Assessing model robustness against edge cases and potential manipulation attempts.
- Regulatory Compliance: Ensuring models meet industry-specific requirements for transparency, fairness, and accountability.
This stage serves as a critical quality gate, preventing problematic models from entering production environments where they could generate business risk or reputational harm.
5. Deployment and Integration
Operationalizing models requires careful integration with existing systems and workflows:
- Infrastructure Provisioning: Establishing compute resources, APIs, and data pipelines that support model serving.
- System Integration: Connecting models with upstream data sources and downstream business applications.
- Performance Optimization: Tuning inference latency, throughput, and resource utilization for production efficiency.
- Rollout Strategy: Implementing gradual deployment approaches (canary releases, A/B testing) that minimize disruption and enable rapid rollback if issues arise.
Platform selection significantly impacts deployment success, with cloud-based MLOps platforms from providers like AWS, Azure, and Google Cloud offering scalable infrastructure specifically designed for AI workloads.
6. Monitoring, Maintenance, and Continuous Improvement
Post-deployment, models require ongoing management to maintain effectiveness:
- Performance Monitoring: Tracking prediction accuracy, latency, and business metrics in real-time.
- Drift Detection: Identifying changes in input data distributions or concept relationships that degrade model performance.
- Automated Retraining: Implementing triggers and workflows that update models with fresh data when performance deteriorates.
- Incident Response: Establishing protocols for addressing model failures, anomalies, or unexpected behaviors.
Organizations implementing automated drift detection reduce model-related incidents by 73%, demonstrating the value of systematic monitoring practices.
4. The Role of MLOps in Scalable AI Delivery
Machine Learning Operations (MLOps) emerged as a discipline specifically designed to address the operational challenges inherent in managing AI systems at scale. Drawing inspiration from DevOps practices in software engineering, MLOps provides frameworks, tools, and cultural approaches that enable reliable, efficient AI lifecycle management.
MLOps: Bridging Development and Operations
MLOps encompasses the extension of DevOps principles to the machine learning lifecycle, addressing unique challenges that distinguish AI systems from traditional software:
- Data Dependencies: Unlike conventional applications with static code, ML models depend on training data that continuously evolves, creating versioning and reproducibility challenges.
- Model Decay: Prediction accuracy naturally degrades over time as real-world conditions shift, requiring continuous monitoring and retraining workflows.
- Experiment Tracking: Data scientists conduct numerous experiments during development, necessitating comprehensive logging of parameters, metrics, and artifacts.
- Multi-stakeholder Collaboration: Successful AI implementation requires coordination across data scientists, ML engineers, software developers, and operations teams with distinct priorities and skillsets.
Core MLOps Capabilities
Effective MLOps implementations typically encompass the following capabilities:
Continuous Integration/Continuous Deployment (CI/CD)Automated pipelines that test, validate, and deploy model updates with minimal manual intervention, enabling rapid iteration while maintaining quality standards.
Version ControlComprehensive tracking of code, data, models, and configurations that enables reproducibility, audit trails, and rollback capabilities when issues emerge.
Automated TestingSystematic validation of model performance, data quality, and integration points that catch issues before production deployment.
Model RegistryCentralized repositories that catalog deployed models with associated metadata (training data, performance metrics, deployment history), facilitating governance and change management.
Infrastructure OrchestrationAutomated provisioning and management of computational resources that optimize cost efficiency while ensuring performance requirements are met.
Monitoring and ObservabilityReal-time tracking of model behavior, system health, and business outcomes that enables proactive issue detection and resolution.
The MLOps Market Landscape
The growing recognition of MLOps' strategic importance has driven substantial market expansion. The global MLOps market was valued at $1.7 billion in 2024 and is projected to grow at a 37.4% CAGR through 2034, reflecting enterprise demand for tools and platforms that simplify AI lifecycle management.
Major technology providers—including Amazon (SageMaker), Microsoft (Azure ML), Google (Vertex AI), and IBM (watsonx)—have developed comprehensive MLOps platforms offering end-to-end lifecycle management capabilities. Additionally, specialized vendors like DataRobot, Databricks, and MLflow provide targeted solutions addressing specific MLOps challenges.
This ecosystem diversity enables organizations to select tools aligned with their existing infrastructure, technical capabilities, and specific use cases, though integration complexity across heterogeneous tool chains remains an ongoing challenge.
5. Comparison: Traditional Model Management vs MLOps-Based Systems
The transition from ad-hoc model management to systematic MLOps practices represents a fundamental shift in how organizations approach AI implementation. Understanding the distinctions illuminates the value proposition of structured lifecycle management.
This comparison underscores why organizations implementing MLOps practices are nearly twice as likely to follow best practices like bias checks, audits, and data protection, ultimately achieving superior outcomes in terms of reliability, cost efficiency, and business value delivery.
6. Challenges in Enterprise AI Lifecycle Management
Despite the clear benefits of structured lifecycle management, enterprises encounter numerous obstacles when implementing MLOps at scale. Recognizing these challenges enables organizations to develop mitigation strategies and realistic implementation roadmaps.
Technical Complexity and Integration Challenges
Modern enterprises operate heterogeneous technology stacks spanning on-premises systems, multiple cloud providers, and legacy applications. Integrating AI workflows across these environments presents significant challenges:
- 35% of product managers cite complex integration with existing systems as a primary concern when adopting MLOps practices.
- Data silos and inconsistent governance across systems complicate efforts to establish unified data pipelines supporting AI development.
- Legacy infrastructure often lacks the computational resources or architectural flexibility required for modern ML workloads.
Cloud platforms from AWS, Azure, and Google Cloud have emerged as preferred foundations for AI implementation, offering specialized services and infrastructure optimized for ML workloads. However, managing AI security, compliance, and governance across cloud environments remains complex, particularly in regulated industries.
Data Quality and Availability
57% of organizations report their data isn't "AI-ready", highlighting the pervasive challenge of preparing enterprise data for AI applications:
- Inconsistent Quality: Missing values, errors, and inconsistencies require extensive cleaning before data becomes suitable for model training.
- Volume and Velocity: Real-time AI applications demand continuous data streams with low latency, straining existing data infrastructure.
- Privacy and Security: Regulatory requirements around data protection (GDPR, CCPA, HIPAA) constrain how organizations collect, store, and utilize data for AI.
- Bias and Representativeness: Historical data often contains biases that models inadvertently learn and perpetuate, creating fairness and compliance risks.
Addressing these data challenges requires investment in data engineering capabilities, governance frameworks, and cultural changes that prioritize data quality as a strategic asset.
Model Drift and Performance Degradation
Unlike traditional software that maintains consistent behavior over time, ML models naturally degrade as the real-world conditions they operate in evolve. This phenomenon, known as model drift, manifests in several forms:
Data Drift: Changes in input feature distributions that violate assumptions models were trained on. For example, shifts in customer demographics or product mix that alter prediction contexts.
Concept Drift: Fundamental changes in relationships between inputs and outputs. For instance, evolving consumer preferences that alter purchase behavior patterns.
Performance Drift: Gradual degradation in prediction accuracy even when data distributions remain stable, often due to adversarial adaptations or environmental changes.
Without proper monitoring, models can see error rates increase by 35% within 6 months, yet 75% of businesses observe AI performance declines over time without proactive monitoring. Effective drift detection requires statistical techniques (Kolmogorov-Smirnov tests, KL divergence) combined with business metric tracking to identify when retraining becomes necessary.
Skills Gaps and Organizational Readiness
Only 20% of executives feel their organizations are highly prepared for AI skills-related challenges, creating human capital constraints that impede AI scaling:
- Data Science Talent Shortage: 50% of organizations expect to need more data scientists in the next year, intensifying competition for scarce talent.
- MLOps Expertise Gap: Few professionals possess the hybrid skillset spanning data science, software engineering, and operations required for effective MLOps implementation.
- Change Management: 67% of organizations cite cultural barriers as significant challenges in AI adoption, as employees resist workflow changes or lack confidence in AI-driven decisions.
Addressing skills gaps requires multifaceted approaches: strategic hiring, upskilling existing staff, partnering with external specialists, and fostering organizational cultures that embrace data-driven decision-making.
Governance, Ethics, and Regulatory Compliance
As AI becomes embedded in critical business decisions, governance frameworks must ensure responsible, compliant, and ethical AI deployment:
- Algorithmic Transparency: Stakeholders increasingly demand explainability for AI-driven decisions, particularly in regulated contexts (credit decisions, healthcare diagnoses, hiring).
- Bias and Fairness: Models must be continuously evaluated for discriminatory outcomes across demographic groups, requiring specialized testing and monitoring capabilities.
- Regulatory Compliance: Emerging regulations like the EU AI Act impose strict requirements around risk assessment, documentation, and human oversight for high-risk AI applications.
Risk management and responsible AI practices remain top priorities for executives, yet many organizations struggle to translate principles into operational practices, creating compliance vulnerabilities.
7. Best Practices for Governance, Monitoring, and Continuous Improvement
Overcoming AI lifecycle management challenges requires adopting proven practices that balance innovation velocity with risk management and operational reliability. The following best practices reflect lessons learned from organizations successfully scaling AI at enterprise level.
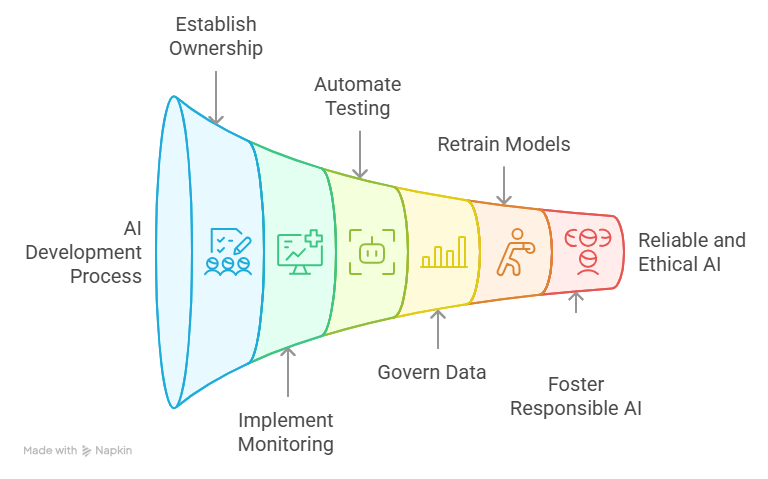
Establish Clear Ownership and Accountability
56% of executives report that first-line teams—IT, engineering, data, and AI—now lead responsible AI efforts, reflecting a shift toward embedded accountability rather than centralized committees. Effective ownership structures include:
- Executive Sponsorship: CEO or board-level oversight ensures strategic alignment and resource commitment, with organizations having CEO-level AI governance being nearly twice as likely to achieve value.
- Cross-Functional AI Councils: Committees spanning business units, IT, legal, and compliance that establish enterprise-wide policies and prioritize investments.
- Embedded AI Teams: Data scientists and ML engineers working within business units, ensuring models address actual operational needs while maintaining technical standards.
Clear ownership accelerates decision-making, reduces ambiguity around responsibilities, and ensures accountability when models underperform or create unintended consequences.
Implement Comprehensive Model Monitoring
Proactive monitoring represents the cornerstone of reliable AI operations, enabling early detection of issues before they impact business outcomes:
Performance Metrics Tracking
- Continuously measure prediction accuracy, precision, recall, and business-specific KPIs in production environments.
- Establish alert thresholds that trigger investigation when metrics deviate from expected ranges.
- Compare performance across demographic segments to identify fairness issues.
Data Drift Detection
- Implement statistical tests (KS tests, KL divergence) comparing production data distributions to training data baselines.
- Monitor both feature-level drift (individual input changes) and multivariate drift (relationship changes across features).
- Establish automated workflows that initiate retraining when drift exceeds predefined thresholds.
System Health Monitoring
- Track infrastructure metrics (latency, throughput, resource utilization) ensuring models meet service level agreements.
- Monitor data pipeline health, catching upstream failures before they propagate to model predictions.
- Implement comprehensive logging enabling root cause analysis when incidents occur.
Modern monitoring platforms like Prometheus and Kafka provide the distributed, real-time capabilities required for enterprise-scale monitoring, while specialized tools like WhyLabs offer purpose-built ML observability features.
Automate Testing and Validation
Automated testing catches issues early in the development lifecycle, preventing problematic models from reaching production:
- Unit Testing: Validate individual model components (feature transformations, prediction functions) ensuring correct implementation.
- Integration Testing: Confirm models integrate properly with upstream data sources and downstream applications.
- Performance Testing: Validate prediction latency and throughput meet requirements under realistic load conditions.
- Bias Testing: Systematically evaluate model outputs across demographic groups, identifying potential discrimination before deployment.
- Adversarial Testing: Assess model robustness against edge cases, data quality issues, and potential manipulation attempts.
Incorporating these tests into CI/CD pipelines ensures consistent quality standards while enabling rapid iteration and deployment.
Establish Robust Data Governance
Organizations investing in data quality and governance are 2.5 times more likely to successfully scale AI, making data governance foundational to lifecycle management:
- Data Quality Standards: Define and enforce requirements for completeness, accuracy, consistency, and timeliness across data sources.
- Lineage Tracking: Maintain comprehensive records of data provenance, transformations, and usage enabling impact analysis and regulatory compliance.
- Access Controls: Implement role-based permissions ensuring only authorized personnel can access sensitive data.
- Privacy Controls: Apply techniques like anonymization, pseudonymization, and differential privacy protecting individual privacy while enabling analytics.
Effective data governance balances accessibility (enabling innovation) with control (managing risk), requiring ongoing investment and executive commitment.
Implement Automated Retraining Workflows
Models require periodic retraining to maintain accuracy as environments evolve. Automated workflows reduce manual burden while ensuring consistency:
- Schedule-Based Retraining: Automatically retrain models at regular intervals (daily, weekly, monthly) based on anticipated drift rates.
- Performance-Triggered Retraining: Initiate retraining when monitoring systems detect accuracy degradation beyond acceptable thresholds.
- Data-Triggered Retraining: Retrain when sufficient new labeled data becomes available, particularly for supervised learning applications.
Automation should include validation steps confirming retrained models outperform existing versions before production deployment, preventing regression.
Foster a Culture of Responsible AI
61% of organizations are at strategic or embedded stages of responsible AI maturity, actively integrating ethical considerations into operations and decision-making. Cultural practices supporting responsible AI include:
- Ethics Training: Ensure all staff working with AI understand ethical principles, potential harms, and mitigation strategies.
- Bias Awareness: Create awareness of how biases enter data and models, fostering vigilance throughout the development process.
- Stakeholder Engagement: Involve affected communities and end users in AI system design, incorporating diverse perspectives.
- Transparency Practices: Document model capabilities, limitations, and potential risks, enabling informed decision-making by users and stakeholders.
These practices extend beyond compliance, building trust with customers, regulators, and employees while reducing reputational risks.
Leverage Standardized Platforms and Tools
Rather than building custom infrastructure for each model, platforms emerged as key players with 72% market share because they provide:
- Consistency: Standardized workflows reduce variability and simplify onboarding for new team members.
- Reusability: Shared components (data pipelines, monitoring dashboards, deployment templates) accelerate development.
- Maintainability: Centralized management simplifies updates, security patching, and compliance enforcement.
- Cost Efficiency: Shared infrastructure and automated resource management optimize spending.
Organizations should evaluate platforms based on integration capabilities with existing systems, support for required frameworks and tools, scalability to anticipated workloads, and alignment with organizational security and compliance requirements.
8. Future Trends: Autonomous ModelOps and Self-Learning Systems
The AI lifecycle management landscape continues evolving rapidly, with several emerging trends poised to reshape how organizations develop, deploy, and maintain AI systems at scale.
Agentic AI and Autonomous Decision-Making
Gartner predicts that by 2028, at least 15% of day-to-day work decisions will be made autonomously through agentic AI, up from essentially zero in 2024. This shift represents a fundamental evolution from AI as a tool augmenting human decisions to AI as an independent agent executing complete workflows.
Agentic AI systems possess several distinguishing characteristics:
- Goal-Oriented Behavior: Rather than responding to individual prompts, agents pursue high-level objectives through multi-step planning and execution.
- Environmental Interaction: Agents observe their environments, take actions, and adapt based on outcomes rather than simply generating predictions.
- Autonomous Adaptation: Advanced agents learn from experience, improving performance without explicit retraining by human operators.
McKinsey reports that 23% of organizations are already scaling agentic AI systems, with an additional 39% experimenting with agent deployments. However, by 2028, 40% of CIOs will demand "Guardian Agents" capable of autonomously tracking, overseeing, or containing the results of other AI agent actions, reflecting concerns about managing increasingly autonomous systems.
Self-Healing and Adaptive Model Architectures
Future MLOps systems will increasingly incorporate self-healing capabilities that detect and remediate issues without human intervention:
- Automated Drift Remediation: Systems that not only detect drift but automatically retrain models using updated data when performance degradation occurs.
- Adaptive Architectures: Models that continuously adjust their internal parameters based on incoming data streams, maintaining accuracy without complete retraining.
- Reinforcement Learning Integration: Models that improve through interaction with production environments, learning from feedback signals embedded in operational workflows.
These capabilities reduce operational burden while improving responsiveness to changing conditions, though they also introduce new challenges around governance, testing, and ensuring reliable behavior of autonomous systems.
Multimodal AI and Unified Lifecycle Management
Gartner predicts that 40% of generative AI solutions will be multimodal by 2027, combining text, images, audio, and video processing within single applications. This evolution creates new lifecycle management challenges:
- Cross-Modal Drift: Performance degradation may occur in one modality while others remain stable, requiring nuanced monitoring approaches.
- Integration Complexity: Multimodal systems coordinate multiple specialized models, increasing deployment and orchestration complexity.
- Validation Challenges: Testing multimodal systems requires diverse datasets and evaluation approaches spanning different data types.
Organizations must adapt their MLOps practices to accommodate these architectures, potentially requiring specialized tools and expertise.
Federated Learning and Distributed Model Training
Federated learning enables model training across distributed datasets without centralizing data, addressing privacy concerns while expanding data access:
- Privacy Preservation: Models train on local data while sharing only model updates, protecting individual privacy and supporting regulatory compliance.
- Cross-Organizational Collaboration: Organizations can collaboratively train models leveraging shared learning without exposing proprietary data.
- Edge Deployment: Models train and update on edge devices, reducing latency and bandwidth requirements for real-time applications.
This approach particularly benefits healthcare, finance, and other regulated sectors where data sharing faces legal and competitive constraints. However, federated learning introduces new technical challenges around communication efficiency, handling heterogeneous data distributions, and preventing adversarial manipulation.
Enhanced Explainability and Governance Tools
As AI systems influence increasingly consequential decisions, demand grows for interpretable models and comprehensive governance frameworks:
- Explainable AI (XAI) Integration: Lifecycle management platforms will increasingly incorporate native explainability tools, making model interpretations readily available to stakeholders.
- Automated Compliance Checking: Governance systems will automatically validate models against regulatory requirements, generating documentation needed for audits.
- Ethical Impact Assessment: Tools will systematically evaluate models for fairness, transparency, and alignment with organizational values before production deployment.
Deloitte's AI Governance Roadmap emphasizes board-level oversight and risk management frameworks that many organizations are beginning to implement, reflecting the strategic importance of governance in AI success.
Sustainability and Green AI
As AI workloads consume increasing computational resources, sustainability considerations are entering lifecycle management practices:
- Energy-Efficient Architectures: Model compression, quantization, and efficient architecture design reduce computational requirements and environmental footprint.
- Carbon-Aware Training: Training workflows that schedule intensive computations when renewable energy availability is high.
- Lifecycle Carbon Accounting: Measuring and reporting the carbon emissions associated with model training, deployment, and inference.
Organizations increasingly recognize that environmental sustainability and cost efficiency align, creating business cases for green AI practices beyond regulatory compliance or corporate social responsibility.
9. Conclusion
The journey from experimental AI models to production systems delivering sustained business value requires comprehensive lifecycle management extending far beyond initial development. As 78% of organizations now deploy AI in at least one business function, the gap between experimentation and operational excellence represents the defining challenge of enterprise AI in 2024 and beyond.
MLOps practices provide proven frameworks for bridging this gap, enabling organizations to deploy, monitor, and continuously improve AI systems at scale. The benefits are substantial: organizations implementing automated drift detection reduce model-related incidents by 73%, while companies with clear AI strategies are five times more likely to realize significant financial benefits.
However, success requires more than adopting tools and platforms. It demands organizational transformation encompassing:
- Clear ownership structures that embed accountability for AI outcomes at executive and operational levels
- Robust data governance that balances accessibility with privacy, security, and quality control
- Comprehensive monitoring that proactively detects performance degradation, drift, and ethical issues
- Automated workflows that reduce manual burden while maintaining consistent quality standards
- Cultural commitment to responsible AI that extends beyond compliance to build stakeholder trust
Looking forward, emerging trends like agentic AI, self-healing systems, and enhanced governance tools will further reshape the AI lifecycle management landscape. Organizations that build mature MLOps capabilities today position themselves to capitalize on these innovations while managing the risks inherent in increasingly autonomous AI systems.